728x90
- XGBBoost 보다 학습시간이 짧음
- 적은 데이터 세트에서 과적합이 발생하기 쉬움, (10,000 이하)
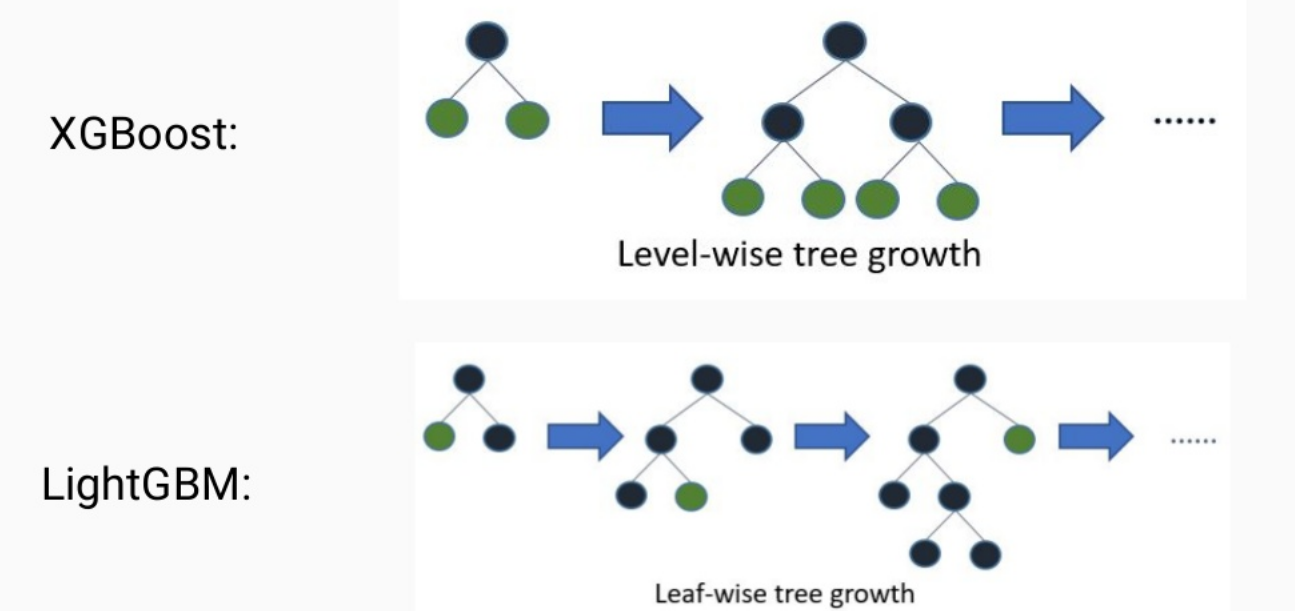
- 트리의 균형을 맞추지 않고 최대 손실값을 가지는 리프노트를 지속적으로 분할하면서 트리가 깊어지고 비대칭적이 트리가 생성됨.
- 예측오류의 손실을 최소화 할 수 있음
- num_iteration: 반복 수행하려는 트리의 갯수, 클 수록 예측가능성이 높아지지만 과적합으로 성능 저하 우려
- learning_rate: 학습률
- boosting: 부스팅 트리를 생성하는 알고리즘 기술
- num_leave:개별 트리가 가질수 있는 최대 리프
- min_data_in_leaf: 과적합 개선을 위해 중요함 파라미터, 값을 크게 하면 트리가 깊어 지는 것을 방지
- max_depth: 트리의 최대 깊이를 규정, 깊어질 수록 과적합 할 수 있음
import lightgbm
lgb = LGBMClassifier()
evlas =[(X_test, y_test)]
lgb.fit(X_train, y_train)
print("train score",lgb.score(X_train, y_train))
pred = lgb.predict(X_test)
pred_proba = lgb.predict_proba(X_test)[:,1]
print("prediction score",accuracy_score(y_test, pred))결과
train score 0.6943428571428572
prediction score 0.6221333333333333
LightGBM은 feature importance 의 plot도 제공한다.
plt.rcParams["figure.figsize"] = (14, 10)
lightgbm.plot_importance(lgb)
plt.show()
자세한 사항은 lightgbm.LGBMClassifier documents에서 확인이 가능하다.
Reference
파이썬 머신러닝 가이드
lightgbm document : https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMClassifier.html#lightgbm-lgbmclassifier
728x90
'Data Science > python & pytorch' 카테고리의 다른 글
| [python] Basics of python (0) | 2023.12.29 |
|---|---|
| [sklearn] sklearn model의 일반적인 형태와 모델들 (0) | 2023.03.06 |