Coursera Stanford Machine Learning Andrew Ng교수의 lecture내용을 정리한 것
Introduction
머신러닝이란?
- Arthur Samuel: 명시적인 프로그래밍을 하지 않고 컴퓨터가 스스로 학습할 수 있는 능력을 연구하는 분야 → informal, 오래된 정의
- Tom Mitchell : 일정 수준의 task (T)와 성과측정(P)에 대하여 컴퓨터 프로그램이 경험으로부터 학습(E)하는 것으로서 P로 측정되는 task(T)의 성과/성능은 학습경험(E)과 함께 향상된다.
예시) 체스게임
E = 많은 체스 게임을 해보는 것
T = 체스게임
P = 다음 체스게임에서 프로그램이 승리할 확률
⇒ 일반적으로 머신러닝은 supervised와 unsupervised learning으로 구분한다.
Supervised Learning
지도학습은 input과 ouput사이의 관계가 있다는 idea로 주어진 데이터 셋의 적절한 결과를 이미 알고 있다.
지도학습은 크게 회귀와 분류로 나눌 수 있다.
- 회귀는 연속적인 결과 값(continuous output)을 예측할 때, 즉 입력변수를 연속함수에 매핑하는 것을 의미한다.
- 분류문제는 이산적인 결과를 예측하는 것으로 입력변수에 이산적 범주를 매핑시키는 것을 말한다.
예시 1 )
집에 크기에 대한 주택가격을 예측한다고 할 때, 주택크기함수에 대한 가격은 연속적인 값을 갖는 것으로 예측이 가능하다. → 회귀문제
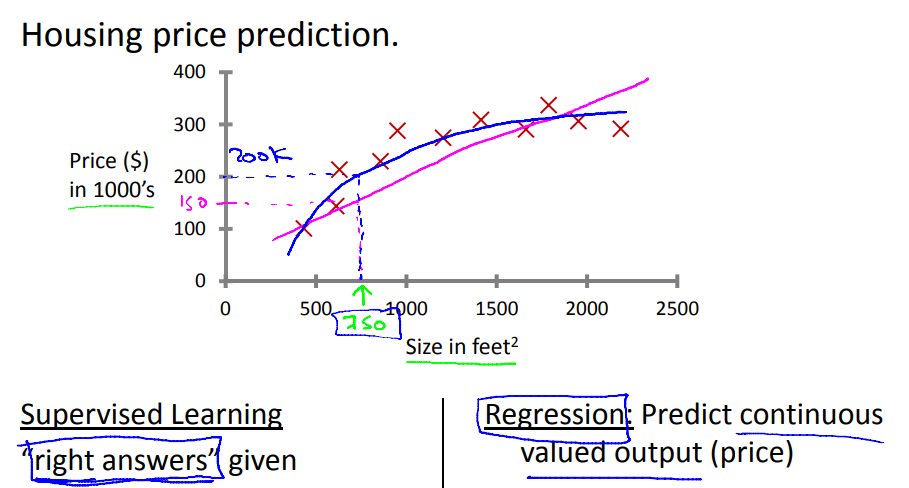
주택매매 시 매매가보다 높거나 혹은 낮은 가격에 판매되는 주택들을 예측 결과로 할 경우 → 분류문제
예시 2)
사람의 얼굴사진에서 나이를 예측하고자 할 때 → 회귀문제
환자의 종양이 양성인지 음성인지 판별예측 → 분류문제

Unsupervised Learning
비지도학습은 결과가 어떻게 생겼는지 거의 또는 전혀 알 수 없는 문제들에서 변수들이 얼마나 영향을 미치는지 알 필요 없이 데이터로부터 구조를 추출해 낸다.
데이터의 변수들 사이의 관계를 바탕으로 clustering을 통해 구조를 추출할 수 있으며 예측결과로 부터 피드백이 없다.
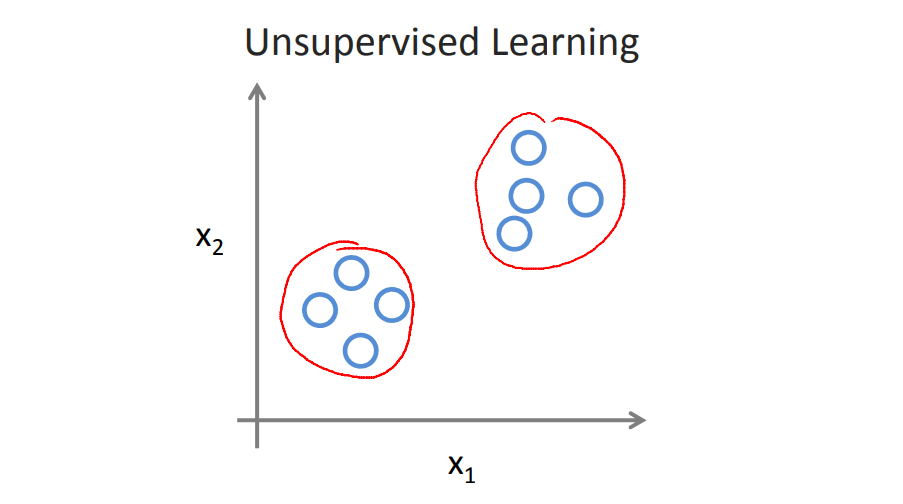
예시)
clustering : 유전자 데이터에서 유전지도를 통해 특정 유전자를 가진 사람들을 분류

Non-clustering:여러 가지 소리가 녹음된 파일에서 음악이나 사람들의 음성을 구별
Refrenece
Machine learning , Coursera, Andrew Ng